
Nos últimos meses o mundo viu na prática o que significa ter parte da internet apoiada em poucos provedores globais de nuvem. Uma grande falha na AWS em outubro, uma interrupção em escala mundial na Azure no mesmo mês, logo depois, um apagão na infraestrutura da Cloudflare em novembro afetaram redes sociais, bancos, companhias aéreas, governos, plataformas de IA, jogos e sistemas de todos os tipos.
A lição precisa ser aprendida. Não basta “estar na nuvem”, é essencial entender como essa nuvem foi desenhada, onde estão os pontos de falha e o quão depende a internet é de camadas centralizadas que, se caem, levam tudo junto com elas.
Encontre neste artigo um resumo sobre o que aconteceu com AWS, Azure e Cloudflare de maneira simples mas sem deixar de lado a profundidade técnica necessária para entender esse fenômeno.
Também fique por dentro de como a HostDime Brasil desenha sua infraestrutura com mais autonomia por data center para garantir mais flexibilidade e menos pontos únicos de falha.
O que aconteceu com AWS, Azure e Cloudflare
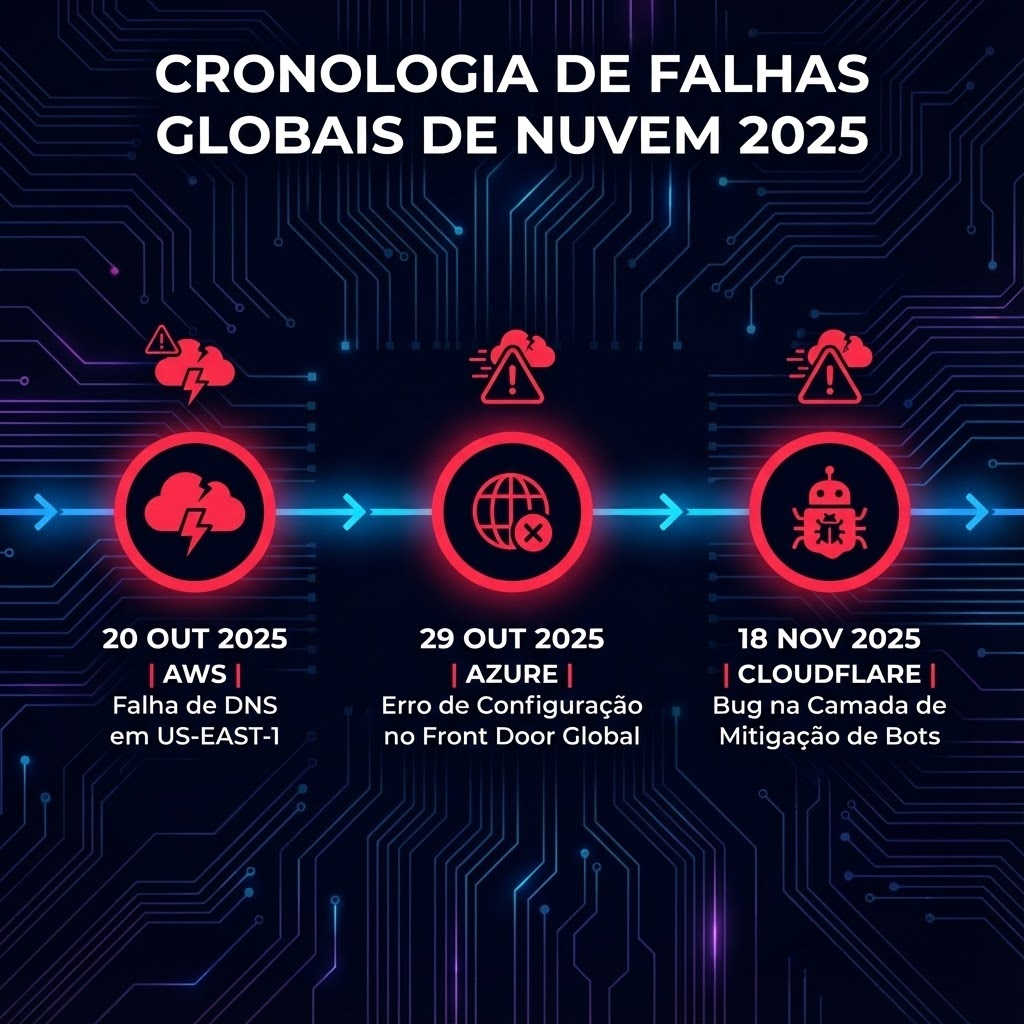
1. AWS: falha de DNS virou problema mundial
Em 20 de outubro, a Amazon Web Services (AWS) sofreu uma grande falha na região US-EAST-1, no estado da Virgínia, uma das mais antigas e mais usadas do provedor.
Segundo informações da Reuters, mais de 500 empresas foram afetadas diretamente, incluindo a própria Amazon e sua assistente virtual Alexa. Entre os servidores afetados estavam grandes plataformas como o Facebook, Prime Video, Mercado Livre, iFood, PicPay, o jogo Fortnite e outros players globais. A falha também paralisou aplicativos e sites de produtividade corporativa, demonstrando o nível de dependência mundial atual de infraestruturas em nuvem.
O que aconteceu?
O problema teve raíz em um subsistema de DNS interno (sistema responsável por traduzir nomes de domínio em endereços IP) do serviço de banco de dados DynamoDB nessa região. Falhas nesse processo impedem que aplicações acessem corretamente os servidores. Quando o DNS interno parou de responder corretamente, milhares de aplicações que dependiam do banco de dados da Amazon começaram a falhar em cascata.
A própria AWS reportou aumento de erros e latência e depois detalhou que a causa estava em falhas de resolução DNS na US-EAST-1. De acordo com análises públicas e dados do Downdetector, mais de 3.500 serviços em mais de 60 países foram afetados, com mais de 17 milhões de relatos de problemas de usuários.
Entre os serviços impactados estavam:
- Aplicativos de consumo: Snapchat, Reddit, Fortnite, Roblox, aplicativos da própria Amazon, assistente Alexa e câmeras Ring.
- Serviços corporativos e governamentais: sistemas de bancos, órgãos fiscais e serviços educacionais em diferentes países.
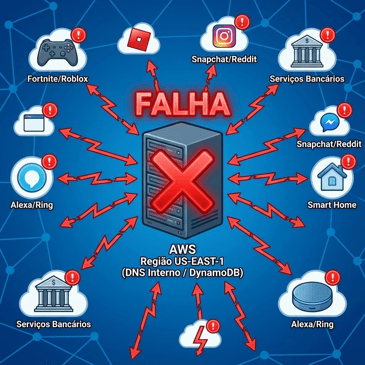
O que chama atenção é o padrão: a forte concentração de serviços críticos em uma única região (US-EAST-1) gera um cadeia de dependências em serviços gerenciados como DynamoDB e IAM. Quando o DNS interno dessa “peça central” falha, a indisponibilidade se espalha por toda essa pilha.
Em outras palavras, um ponto lógico único de falha dentro da região acabou afetando uma parte enorme da internet.
2. Azure: erro de configuração no Azure Front Door parou aplicações globais
Após poucos dias do primeiro “apagão global” em 29 de outubro, foi a vez da Microsoft Azure enfrentar uma falha em âmbito mundial. O incidente durou cerca de oito horas, degradando ou derrubando serviços em várias regiões.
O que aconteceu?
A Microsoft afirmou que uma alteração de configuração defeituosa em uma rede de distribuição de conteúdo chamada Azure Front Door (AFD), desencadeou a interrupção. Segundo a empresa, um número significativo de “nós” – como são conhecidos os Pontos de Presença do AFD – deixou de carregar corretamente, levando a aumento da latência, timeouts e erros de conexão para os serviços subsequentes.
Em resumo, os "nós" são os "saltos" na rede global da Microsoft que o Front Door usa para reduzir latência e acelerar aplicações. São Pontos de Presença (PoP) capazes de rotear o tráfego para o backend mais próximo e saudável.
Pontos técnicos relevantes:
- A própria Microsoft divulgou que a causa foi uma mudança de configuração inadvertida no Azure Front Door (AFD), sua plataforma global de entrega de conteúdo (Content Delivery Network) e entrega de aplicações.
- Essa mudança introduziu um estado de configuração inválido em diversos “nós” do AFD, impedindo que essas instâncias carregassem corretamente.
- À medida que os “nós” com erro saíam do grupo de servidores, o tráfego era redistribuído para os próximos, que acabavam sobrecarregados, ampliando o problema para regiões que inicialmente não estavam afetadas.
- Mecanismos de proteção automática que deveriam barrar esse tipo de configuração problemática não atuaram da forma esperada por causa de um bug, o que deixou a mudança seguir adiante.
Quem sentiu na pele:
- Linhas aéreas, como Alaska Airlines, tiveram check-in e sistemas de reservas prejudicados.
- Setor financeiro e varejo: bancos, redes de varejo e empresas de telecom tiveram instabilidades em sites, apps e APIs.
- Serviços da própria Microsoft: Microsoft 365, Outlook, Xbox Live, Copilot, Minecraft e outros tiveram acesso degradado.
Mais uma vez o problema apontou para o risco de contar com uma única camada global central, como o Front Door, usada por milhares de serviços, internos e de clientes. Uma mudança de configuração nessa camada central resultou em falha global, por falta de isolamento suficiente entre domínios e regiões de configuração.
3. Cloudflare: bug em camada de mitigação de bots derruba parte da internet
Em 18 de novembro e, novamente, em 5 de dezembro, a Cloudflare, responsável por acelerar e proteger cerca de 20% dos sites do mundo, também sofreu uma falha em larga escala.
Sistemas de sites famosos como ChatGPT, X, Canva, Discord, Grindr, Spotify e Uber ficaram fora do ar.
O que aconteceu?
Segundo a própria empresa e diversos veículos, a origem não foi um ataque hacker ou atividades maliciosas como se especulou no início, e sim uma mudança planejada para mitigar uma vulnerabilidade e desativar uma ferramenta interna por meio do sistema de configuração global.
O WAF da Cloudflare (aplicação web que atua como um escudo, filtrando e monitorando o tráfego HTTP/S entre a internet e um site ou aplicativo) precisa ler o corpo das requisições HTTP para inspecionar padrões, bloquear conteúdos maliciosos e aplicar regras de segurança. Para isso, cada solicitação tem seu corpo armazenado em buffer (espaço temporário na memória criado para segurar dados que ainda não foram totalmente processados) na memória.
Até então, esse buffer tinha limite de 128 KB. Por causa de uma vulnerabilidade considerada crítica, a Cloudflare iniciou um processo de aumentar esse limite para 1 MB.
A mudança estava sendo aplicada de forma gradual até que uma ferramenta interna usada para testar e validar regras do WAF começou a apresentar erros. Como era uma ferramenta não essencial para o tráfego de produção, a Cloudflare decidiu desativá-la temporariamente usando o sistema de configuração global.
A desativação da ferramenta gerou um estado de configuração inválido. Esse estado levou o módulo de regras do WAF a entrar em falha durante a execução.
Quando esse módulo deixa de carregar, o proxy simplesmente não consegue completar o processamento das requisições. Como resultado, a rede passou a retornar erros HTTP 500 para qualquer site atendido pelo proxy afetado.
.png?width=638&height=359&name=%5BBLOG%5D%20Imagens%20e%20elementos%20(14).png)
Em resumo: uma alteração de configuração global gerou um comportamento inesperado no mecanismo que processa as regras de segurança do Web Application Firewall (WAF). O proxy não soube lidar com a ausência da função esperada, entrou em pane e derrubou tudo o que dependia dessa camada.
- Embora nem todos os data centers da Cloudflare tenham parado, a parte afetada foi grande o suficiente para deixar milhares de sites e APIs indisponíveis.
Serviços afetados:
- Plataformas de grande uso público como X (Twitter), ChatGPT, Canva, além de outros serviços online, sites de órgãos reguladores e instituições financeiras.
Ponto técnico chave:
- A camada de segurança e mitigação de bots da Cloudflare ficam no fluxo normal do conteúdo, lado a lado, ocupando apenas o espaço necessário no caminho do tráfego (inline). Quando essa camada central falhou, passou a bloquear ou interromper acessos mesmo que outras camadas de CDN ou DNS estivessem saudáveis.
Muita centralização, pouco isolamento
Analisando as três falhas, vemos um padrão claro: dependência de um componente lógico global ou de uma região crítica.
- AWS: DNS interno e DynamoDB concentrados em US-EAST-1, região usada por uma quantidade enorme de serviços mundiais. Ookla
- Azure: Azure Front Door como camada global de entrada para aplicações e conteúdo. IT Pro
- Cloudflare: camada de mitigação de bots utilizada como filtro central por grande parte do tráfego. Tom's Hardware
Configuração e controle centralizados também dificultam a continuidade de operações: pequenas mudanças em pipelines de configuração atingem milhares de clientes de uma vez, pois a mesma infraestrutura lógica é compartilhada por todos. IT Pro
Por consequência, quando um componente central falha (DNS interno, CDN global, camada de segurança inline), serviços que dependem direta ou indiretamente dele passam a falhar em cascata.
Os três incidentes reforçam uma mensagem importante: a questão não é “se falhas acontecem ou não”. A pergunta correta é:
Como a arquitetura foi desenhada para que uma falha fique contida em um escopo pequeno ao invés de derrubar o mundo inteiro junto?
É exatamente aqui que o modelo da HostDime Brasil se diferencia.
Como desenhamos a HostDime Brasil para evitar esse tipo de cenário?
Na HostDime, nós também lidamos com riscos físicos, de rede e de software, como qualquer operador sério de data center. A diferença está em como distribuímos e isolamos esses riscos, e em como garantimos ao cliente liberdade para montar sua própria arquitetura em cima da nossa infraestrutura.
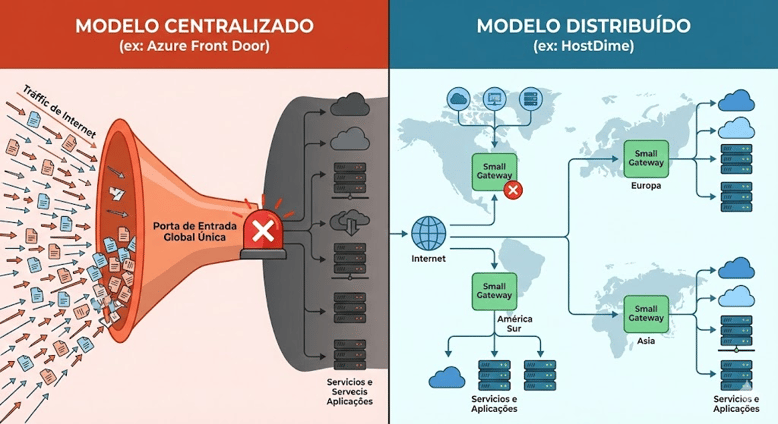
1. Autonomia por data center e distribuição geográfica
No Brasil, operamos dois data centers, em João Pessoa (PB) e São Paulo (SP), além de nossos outros data centers no México, Colômbia, Estados Unidos, Índia e Inglaterra.
- Neles oferecemos colocation, servidores dedicados, cloud server, entre outros.
- A rede da HostDime utiliza múltiplas conexões redundantes com diversos provedores de backbone e IX.br, o que melhora latência e, principalmente, resiliência de rota.
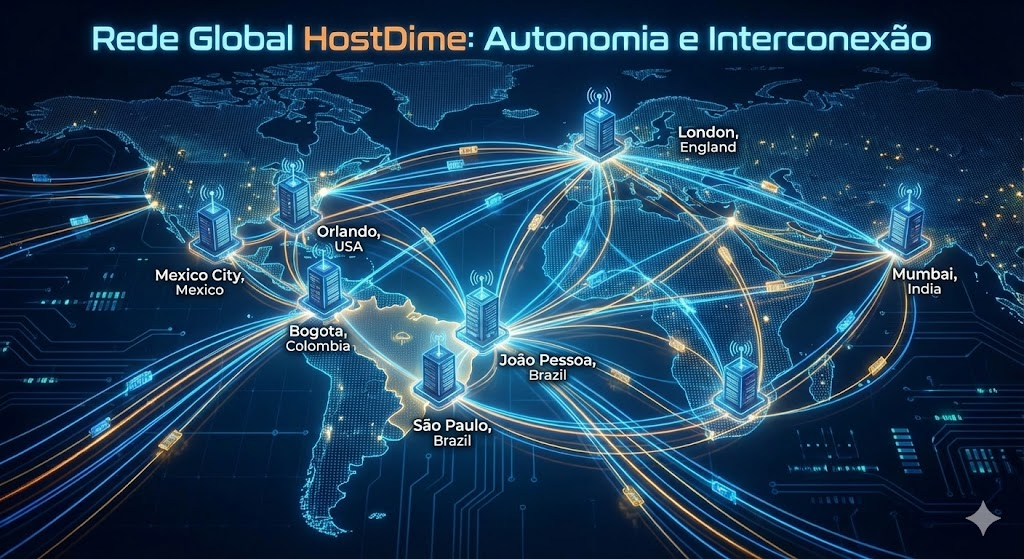
Globalmente, a HostDime opera uma rede de data centers edge em vários países, sempre com foco em proximidade geográfica, baixa latência e independência local. Isso significa que:
- Não existe uma única região “mágica” que concentra tudo, como a US-EAST-1 na AWS.
- Projetamos as soluções para que cada site tenha vida própria, com conectividade e infraestrutura suficientes para operar de forma autônoma.
2. Rede projetada sem ponto único de falha
Nossa rede é construída com roteadores de borda e núcleo redundantes, além de switches de acesso em HA com 200 Gbps de capacidade por rack. Esse desenho é explicitamente pensado para ser um network fabric sem ponto único de falha, com tráfego balanceado entre equipamentos redundantes.
Na prática, isso significa que:
- Uma falha em um roteador específico não deve derrubar todo o data center. O tráfego é redistribuído automaticamente pelos caminhos redundantes.
- Dificilmente uma falha isolada derrubaria integralmente um data center da HostDime, porque mesmo dentro do data center evitamos centralização excessiva, tanto de rede quanto de energia e refrigeração, com certificado Tier III de redundância e manutenção simultânea.
- Nós não adotamos um único software controlador central de rede ou segurança que concentre decisões de todos os data centers ou de todos os clientes ao mesmo tempo
- Em vez disso, cada ambiente de cliente é segmentado e pode ter seus próprios elementos de rede e segurança, reduzindo a chance de uma mudança global única causar um efeito cascata similar ao de Azure Front Door ou da camada de bot mitigation da Cloudflare.
3. O cliente escolhe a arquitetura
Na HostDime, a oferta não se limita à “nuvem pública padrão”. Nós entregamos:
- Colocation em racks, cages ou áreas privativas.
- Servidores bare metal e dedicados, totalmente configuráveis, com acesso a recursos como IPMI e customização de hardware.
- Cloud servers, Firewall as a service, Backup, Armazenamento em Bloco, Clusters e soluções de nuvem privada.
Com isso, o cliente pode:
- Projetar sua própria arquitetura de hardware, sistema operacional e rede, usando seus próprios appliances, firewalls, balanceadores, storage e bancos de dados em colocation;
- Combinar bare metal para bancos de dados de alta performance com cloud para camadas de aplicação elásticas;
- Distribuir a solução entre um único data center ou entre múltiplos data centers da HostDime para ter planos de DR e alta disponibilidade multi-site.
Tudo isso sem depender de um controlador central de rede ou de uma camada obrigatória de CDN ou segurança compartilhada por todos os clientes.
4. Segurança e rede sem “camada única obrigatória”
Nos incidentes de Cloudflare e Azure, uma camada lógica central falhou e acabou levando junto serviços que não tinham qualquer problema local.
Na HostDime, o desenho é diferente: a camada de firewall não é um equipamento único e central por onde passa todo o tráfego de todos os clientes. Aqui, cada cliente pode ter firewalls dedicados ou soluções específicas, seja em appliances físicas em colocation ou em appliances virtuais dentro da nossa nuvem.
Esse modelo de operação garante que uma eventual falha de configuração em um firewall de um cliente não se espalhe automaticamente para toda a base e vice-versa. Essa filosofia vale também para outros componentes:
- DNS pode ser do próprio cliente, em servidores dedicados, ou consumido de forma distribuída, com ou sem anycast.
- Balanceadores, proxies e WAFs podem ser desenhados em camadas específicas por aplicação, em vez de um grande “front door” único.
5. Anycast, IP próprio e estratégias de DR entre data centers
Outra diferença importante é a forma como oferecemos flexibilidade avançada de rede:
- O cliente pode utilizar seu próprio bloco de IP, que nós anunciamos por BGP na nossa infraestrutura. Isso traz autonomia e facilita migrações e estratégias de multi-homing.
- É possível desenhar arquiteturas com anycast, em que o mesmo IP é anunciado a partir de múltiplos data centers HostDime, permitindo alta disponibilidade geográfica: se um site tiver indisponibilidade, o tráfego converge para o outro, sem a necessidade de alterar DNS manualmente.
- Oferecemos storages capazes de replicar blocos de dados dentro e entre data centers, o que facilita cenários de Disaster Recovery, com réplicas assíncronas ou síncronas conforme o projeto. Isso permite RTO e RPO ZERO quando ofertamos Active Cluster dentro do mesmo data center e RTO e RPO de no máximo 5 minutos quando ofertamos Active DR entre nossos data centers.
Na prática, isso permite cenários como:
- Aplicação crítica com instâncias em João Pessoa e São Paulo, com sessão e dados replicados, atendendo usuários da região norte e sul do Brasil com baixa latência.
- Serviços de API com IP anycast, entregues simultaneamente em múltiplos data centers, com failover transparente em caso de problema localizado.
- Ambientes de banco de dados em bare metal em um data center e réplica quente em outro, com plano definido de ativação em caso de desastre.
4. Compare: modelo centralizado x modelo HostDime
Qual a diferença de modelos globais centralizados para a operação do data center da HostDime Brasil? Confira a tabela comparativa a seguir para entender de maneira prática:
|
Aspecto técnico |
AWS (20/10/2025) |
Azure (29/10/2025) |
Cloudflare (18/11/2025) |
HostDime Brasil |
|
Componente que falhou |
DNS interno para DynamoDB na região US-EAST-1 |
Configuração do Azure Front Door, CDN global |
Camada de mitigação de bots, com arquivo de configuração gerado automaticamente |
Rede multi-data center com roteadores e switches redundantes, sem controlador único global de rede ou segurança |
|
Tipo de ponto único de falha |
Região crítica muito concentrada (US-EAST-1) e DNS interno compartilhado |
CDN global central, compartilhada por serviços Microsoft e clientes |
Camada de segurança inline compartilhada por grande parte do tráfego |
Evitamos elementos únicos globais, cada data center tem autonomia de rede e os clientes podem ter appliances dedicados por ambiente |
|
Escopo do impacto |
Global, milhares de serviços e milhões de usuários |
Global, afetando Azure, Microsoft 365, Xbox e grandes empresas |
Global, afetando X, ChatGPT, Canva, órgãos públicos e outros |
Impacto tende a ser localizado em um ambiente específico, graças a isolamento entre clientes e entre data centers |
|
Origem imediata |
Falha de subsistema de DNS interno para APIs de banco de dados |
Mudança de configuração inválida no Azure Front Door, com bug em mecanismos de proteção |
Arquivo de configuração usado para mitigar bots excedeu limites e acionou bug latente |
Arquitetura orientada a redundância e segmentação, com mudanças de configuração e de política aplicadas em escopos menores e mais controlados |
|
Caminho de recuperação |
Mitigação do DNS, normalização gradual de serviços dependentes |
Congelamento de novas configurações AFD, rollback para última configuração válida |
Correção no serviço de bots, reativação progressiva dos serviços e dashboards |
Desenhos de HA e DR definidos por cliente, com possibilidade de manter serviços ativos em múltiplos data centers ao mesmo tempo |
|
Opções nativas de arquitetura do cliente |
Forte incentivo a concentrar tudo em algumas regiões e serviços gerenciados centrais |
Forte uso de serviços globais como AFD e componentes compartilhados |
Tráfego passa por camada de segurança global da Cloudflare |
Cliente pode combinar colocation, bare metal, nuvem e serviços de rede, incluindo uso de IP próprio, anycast e replicação entre data centers |
5. Direto ao ponto
Se formos traduzir tudo isso em termos bem simples para decisão no cenário de business:
-
O que vimos com AWS, Azure e Cloudflare?
- Um problema “dentro da casa deles” virou problema de milhares de empresas ao mesmo tempo.
-
- O motivo é a dependência de componentes centrais compartilhados, que funcionam como “interruptores gerais” de luz. Quando esse interruptor falha, muita gente fica no escuro.
- O motivo é a dependência de componentes centrais compartilhados, que funcionam como “interruptores gerais” de luz. Quando esse interruptor falha, muita gente fica no escuro.
-
O que fazemos diferente na HostDime Brasil?
- Em vez de um único interruptor geral, criamos várias chaves independentes.
-
- Cada data center é autônomo, com rede e infraestrutura redundantes, e dentro dele os ambientes de clientes também são segmentados.
-
- Você pode montar sua arquitetura do jeito que faz sentido para o seu negócio, combinando colocation, bare metal, nuvem, DR entre data centers e opções avançadas de rede.
-
- Não existe um único software central de rede ou segurança que, se falhar, desligue todos os clientes de uma vez.
- Não existe um único software central de rede ou segurança que, se falhar, desligue todos os clientes de uma vez.
Em resumo:
Nosso foco é conter falhas, não ampliá-las.
Enquanto a concentração em poucos provedores globais com planos de controle muito centralizados vem mostrando seu risco, a HostDime Brasil acredita em um modelo de infraestrutura mais distribuído, flexível e sob medida capaz de colocar negócio em uma posição muito mais segura frente a eventos desse tipo.
Atualização: uma nova falha na Cloudflare foi registrada na última sexta-feira (5).
A pane foi causado pelo mesmo motivo do último caso: alterações internas feitas durante uma tentativa de mitigar uma vulnerabilidade. Segundo a declaração da empresa no X, a instabilidade durou 25 minutos e afetou cerca de 28% do tráfego global HTTP.
A repetição de falhas em players como a Cloudflare escancara a vulnerabilidade estrutural da centralização da internet.



